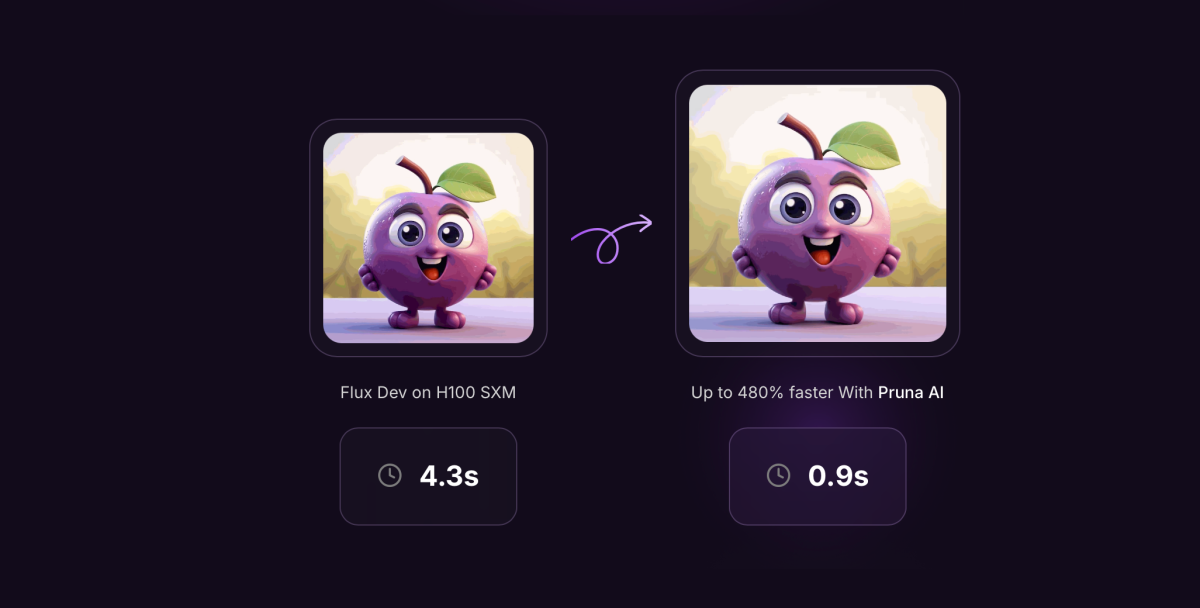

Pruna AI, una innovadora startup europea dedicada al desarrollo de algoritmos de compresión para modelos de Inteligencia Artificial (IA), ha anunciado que su framework de optimización de modelos de IA será liberado como código abierto. Este avance se llevará a cabo el día jueves, ofreciendo a la comunidad global de desarrolladores y empresas la oportunidad de acceder a su tecnología puntera, diseñada para mejorar la eficiencia de los modelos de IA sin comprometer la calidad.
El Enfoque de Pruna AI: Eficiencia y Escalabilidad para Modelos de IA
Pruna AI ha trabajado durante años en el desarrollo de un marco de optimización que aplica diversas técnicas de eficiencia a los modelos de IA, tales como almacenamiento en caché, poda, cuantización y destilación. Estas técnicas tienen como objetivo reducir el tamaño y los requisitos computacionales de los modelos de IA, mejorando su rendimiento en entornos de producción.
Según John Rachwan, cofundador y director de tecnología de Pruna AI, “el enfoque de nuestra empresa es crear un marco que no solo comprima los modelos, sino que también permita evaluar la calidad y el rendimiento tras la compresión”. Pruna AI se enfoca en proporcionar herramientas que no solo apliquen estas técnicas de manera efectiva, sino que también estandaricen el proceso de guardado, carga y evaluación de los modelos comprimidos.
Este marco de trabajo es especialmente relevante en un momento en que la comunidad de IA se enfrenta a la necesidad de hacer más eficientes los grandes modelos de lenguaje (LLMs), modelos de difusión, modelos de visión por computadora y de conversión de voz a texto. Estos modelos, aunque altamente efectivos, son conocidos por sus elevados costos computacionales y su necesidad de grandes cantidades de datos para funcionar adecuadamente.
Técnicas de Optimización: Compresión sin Pérdida Significativa de Calidad
La compresión de modelos de IA implica una serie de técnicas diseñadas para reducir el tamaño de un modelo sin perder demasiado en cuanto a precisión y rendimiento. Las técnicas utilizadas por Pruna AI incluyen:
- Poda (Pruning): Este proceso implica eliminar conexiones innecesarias dentro del modelo de IA, lo que reduce el tamaño del modelo sin perder funcionalidad esencial.
- Cuantización (Quantization): En lugar de utilizar números de punto flotante de alta precisión, se utilizan representaciones de menor precisión, lo que reduce tanto el tamaño como la carga computacional.
- Destilación (Distillation): Una técnica que implica entrenar a un modelo más pequeño (el modelo “estudiante”) para imitar el comportamiento de un modelo grande y complejo (el modelo “maestro”), preservando así el rendimiento mientras se reduce el tamaño.
- Almacenamiento en Caché (Caching): Optimización de la carga y el uso de datos para reducir la redundancia y mejorar la eficiencia.
Estas técnicas no solo permiten reducir el tamaño de los modelos, sino que también contribuyen a hacerlos más rápidos y menos costosos de ejecutar. Sin embargo, un desafío importante en este campo es evitar la pérdida de calidad del modelo tras la compresión. Pruna AI ha desarrollado un sistema que evalúa el impacto de la compresión en la calidad y el rendimiento del modelo, asegurando que el modelo comprimido siga ofreciendo resultados precisos y rápidos.
“Si utilizamos una metáfora, lo que hacemos es similar a lo que Hugging Face ha logrado con los transformers y los difusores. Ellos han estandarizado cómo llamar, guardar y cargar estos modelos. Nosotros estamos haciendo lo mismo, pero enfocados en métodos de eficiencia”, explicó Rachwan.
La Oferta de Pruna AI: Accesibilidad para Todos
Lo que distingue a Pruna AI de otras soluciones en el mercado es su enfoque integral. Mientras que otras herramientas en el mundo de código abierto tienden a centrarse en una única técnica de optimización, Pruna AI ofrece una solución todo-en-uno que permite combinar diferentes métodos de compresión de manera sencilla.
Esta plataforma abierta es de particular interés para los desarrolladores que trabajan en modelos grandes de IA, pero también es útil para empresas más pequeñas que buscan optimizar sus modelos sin tener que desarrollar sus propias soluciones internamente.
Modelos de IA Soportados y Casos de Uso
Pruna AI soporta una amplia variedad de modelos de IA, desde modelos de lenguaje grandes hasta modelos de difusión, conversión de voz a texto y visión por computadora. Sin embargo, actualmente la startup está concentrando sus esfuerzos en la optimización de modelos generativos de imágenes y videos, un área con una creciente demanda debido a los avances en la creación de contenidos generados por IA.
Entre los usuarios actuales de Pruna AI se encuentran empresas como Scenario y PhotoRoom, que utilizan el framework de compresión para mejorar la eficiencia de sus sistemas de generación de imágenes. Con la versión de código abierto, Pruna AI espera expandir su base de clientes y colaborar con más empresas en diversas industrias.
La Visión Futuro: Agente de Optimización y Modelos Comprimidos
Además de su versión de código abierto, Pruna AI también ofrece una opción de nivel empresarial con características avanzadas de optimización. Una de las características más emocionantes que la empresa planea lanzar próximamente es el “agente de compresión”. Este agente permitirá a los desarrolladores cargar su modelo, establecer un objetivo de rendimiento (por ejemplo, velocidad sin perder más del 2% de precisión) y dejar que el agente realice el proceso de compresión de manera automática.
“Este agente de optimización tomará las decisiones por ti. Es como si le dijeras, ‘Quiero más velocidad, pero no quiero perder más de un 2% de precisión’, y el agente hará el trabajo. Esto ahorrará mucho tiempo a los desarrolladores”, agregó Rachwan.
En términos de monetización, Pruna AI cobra por hora por su versión profesional. Este modelo de precios es similar al alquiler de GPUs en servicios de la nube como AWS, lo que lo hace accesible y flexible para las empresas que necesitan un alto rendimiento pero no tienen los recursos para desarrollar sus propios sistemas de compresión internamente.
Resultados Tangibles: Ahorro en Costos e Incremento en la Eficiencia
Uno de los principales atractivos de Pruna AI es el ahorro significativo que las empresas pueden lograr en costos de infraestructura y ejecución de modelos de IA. Por ejemplo, utilizando el framework de compresión de Pruna AI, un modelo Llama se redujo hasta ocho veces en tamaño sin una pérdida significativa de calidad. Esto no solo reduce el costo de almacenamiento y la memoria, sino que también mejora la eficiencia en la ejecución de inferencias.
Rachwan tiene claro que la compresión de modelos es una inversión que se paga sola con el tiempo. “Cuando tu modelo es una parte crítica de tu infraestructura de IA, optimizarlo no solo mejora el rendimiento, sino que también reduce los costos operativos a largo plazo”, señaló.
La Financiación y el Futuro de Pruna AI
Pruna AI recaudó recientemente una ronda de financiamiento de semilla por un total de 6.5 millones de dólares. Los inversionistas incluyen nombres destacados como EQT Ventures, Daphni, Motier Ventures y Kima Ventures. Este financiamiento permitirá a la startup continuar desarrollando su tecnología y expandir su impacto en la industria de la IA.
Con un enfoque claro en la optimización de modelos generativos, Pruna AI tiene un futuro prometedor en el campo de la IA, y su plataforma de código abierto seguramente se convertirá en una herramienta clave para empresas que buscan mejorar la eficiencia de sus modelos de IA sin comprometer la calidad